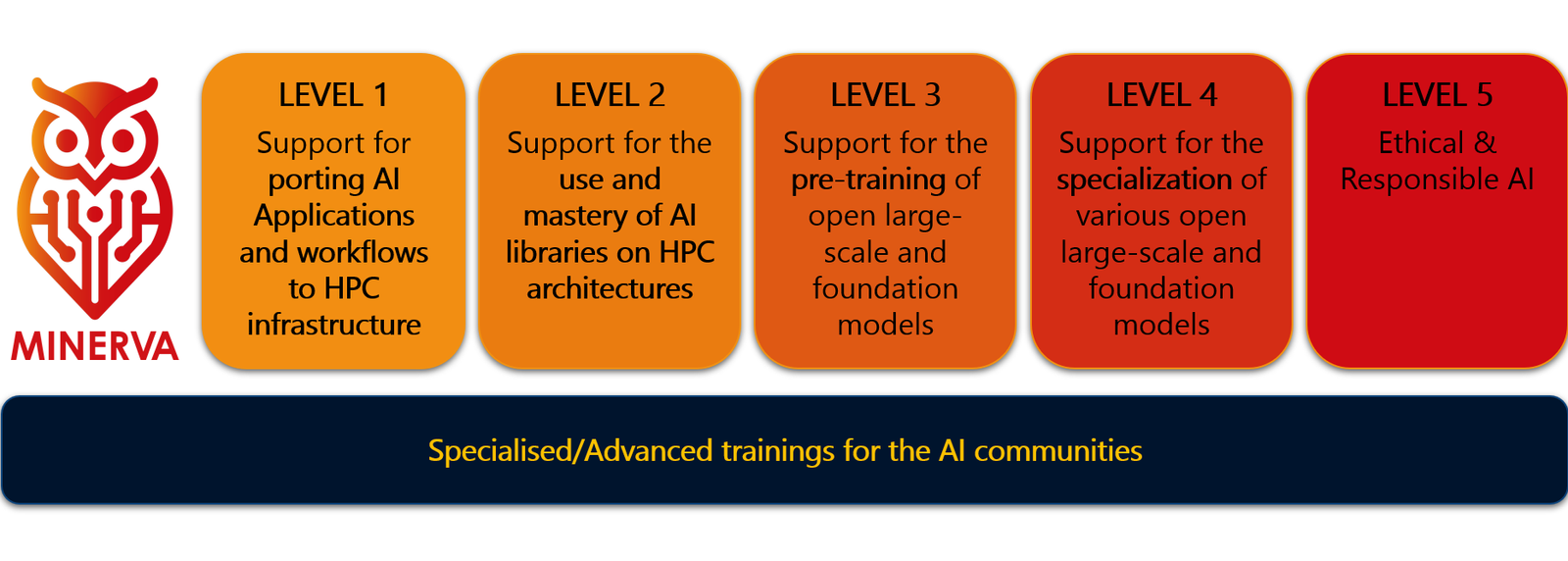
A Tiered Approach to High-Performance AI
From foundational support to advanced optimization, MINERVA’s services scale to meet the evolving needs of the European AI community.
NOTE: services are open also to EU-based private entities. When providing support services to such entities, however, potential obligations related to state aid regulations might apply.
We will now provide an overview of the service level structure. To know more about the details of the support you are entitled to receive when you ask for our services, proceed to the Support page.
A full description of our service portfolio is available here in pdf format:
Support for porting AI Applications and workflows to HPC infrastructure (L1)
We aim to help AI user communities use HPC infrastructures.
We support AI teams in accessing and effectively using HPC infrastructures. Services include assistance with resource requests to national and EuroHPC JU calls, adapting applications and workflows to HPC environments, data preprocessing, and storage optimization. Users also receive help with development and execution tools like Jupyter Notebook or Kubernetes, as well as infrastructure-specific documentation.
Interested? Ask here.
Support for the use and mastery of AI libraries on HPC architectures (L2)
We focus on supporting the use and mastering of AI libraries on HPC architectures, going beyond basic porting.
The focus is on optimizing the use of AI libraries on HPC systems. This includes scaling workloads for efficient training and deployment, adapting software to hardware accelerators, and addressing regulatory concerns related to responsible AI. Support may also involve adapting large multimodal models and exploring techniques to obtain compact model variants.
Interested? Ask here.
Support for the pre-training of open large-scale and foundation models (L3)
We focus on providing expert guidance to AI practitioners in the customization of open foundation models.
Our support is dedicated to enabling the pre-training of large-scale and open foundation models on HPC infrastructure. Activities include guidance on adapting and scaling models for specific tasks, optimizing performance, integrating diverse data types, and implementing efficient model compression techniques.
Interested? Ask here.
Support for the specialization of various open large-scale and foundation models (L4)
We guide users in implementing classic fine-tuning and specialization methods for large scale and foundation models, specifically for scaled use on HPC infrastructure.
This includes support for parameter-efficient training, advanced methods like Retrieval-Augmented Generation (RAG), and preference alignment. Efficient evaluation and inference strategies are also part of this level.
Interested? Ask here.
Guidance and Support on regulations on ethical and responsible AI (L5)
We assist users requesting support to address emerging challenges from regulations on ethical and responsible AI in their applications.
Support at this level helps users address challenges stemming from EU regulations and best practices in ethical AI. Services include evaluating datasets for inappropriate content, designing fair training workflows, and advising on AI compliance. This support is delivered in collaboration with external service providers and other EU-funded projects.
Interested? Ask here.
Specialised/Advanced trainings for the AI communities
We prepare and implement specialized training activities to provide users with the expertise to efficiently use supercomputers hosted by participating partners and other EuroHPC supercomputers.
These training activities are dedicated to both academic and industrial users, bridging the knowledge gap on the efficient use of HPC resources typically experienced by the AI community. Training involves guidance on HPC architectures and schedulers and promotes the adoption of common methodologies and software stacks, including libraries, tools, and distributed training pipelines.
We also cover available open-source models, like open foundation models, and how to efficiently adapt them to user needs. Training includes ramp-up workshops for entry-level users for a fast start in HPC environments, as well as specialized and domain-specific courses dedicated to large-scale use cases.